In brief. AI coding tools do well on small tasks and fray on big projects — sessions drift, decisions contradict, quality decays. Crucible’s hypothesis about why: it’s a coordination problem, not an intelligence problem. Put one shared, structured record of the project at the center, have every agent read and write it, and govern each step with deterministic gates — and coordination, quality enforcement, an audit trail, and a learning loop all fall out of that one choice. The claim is narrower than it sounds: Crucible doesn’t design your architecture or supply your judgment — you do. It keeps the execution coherent with the architecture you chose and enforces the standards you encode, at a scale you couldn’t sustain by hand. The evidence so far is an existence proof: Crucible built Crucible — one operator, about three months. It works for me; whether it works for you I don’t know yet, and the free alpha is how I find out. What follows is the architecture, in enough detail to judge it.
The path this post walks — five parts, each answering the question the one before it raises:
- Why this, why now — the coherence wall, why it’s a coordination problem, and what I’m not claiming
- The design — one shared record, agents that do the whole job, and the seven movements that fall out
- The structure — the real stack, everything running on your machine
- Today, and what’s next — the existence proof (Crucible built Crucible), why it’s free, and alpha vs. Pro
- In closing — it works for me, and it compounds
The coherence wall
The tools have crossed a real line — AI agents can operate on files, run tests, and do genuine engineering work, not just autocomplete in a chat. They hold up on small, well-scoped work, then fall apart as the project grows: too many files, too many decisions, too much context that has to stay consistent across sessions. The model starts re-deriving things it figured out yesterday. Decisions contradict. Quality drifts. It’s one of the most widely reported patterns in AI-assisted development — and I think the gap is specific and fixable.
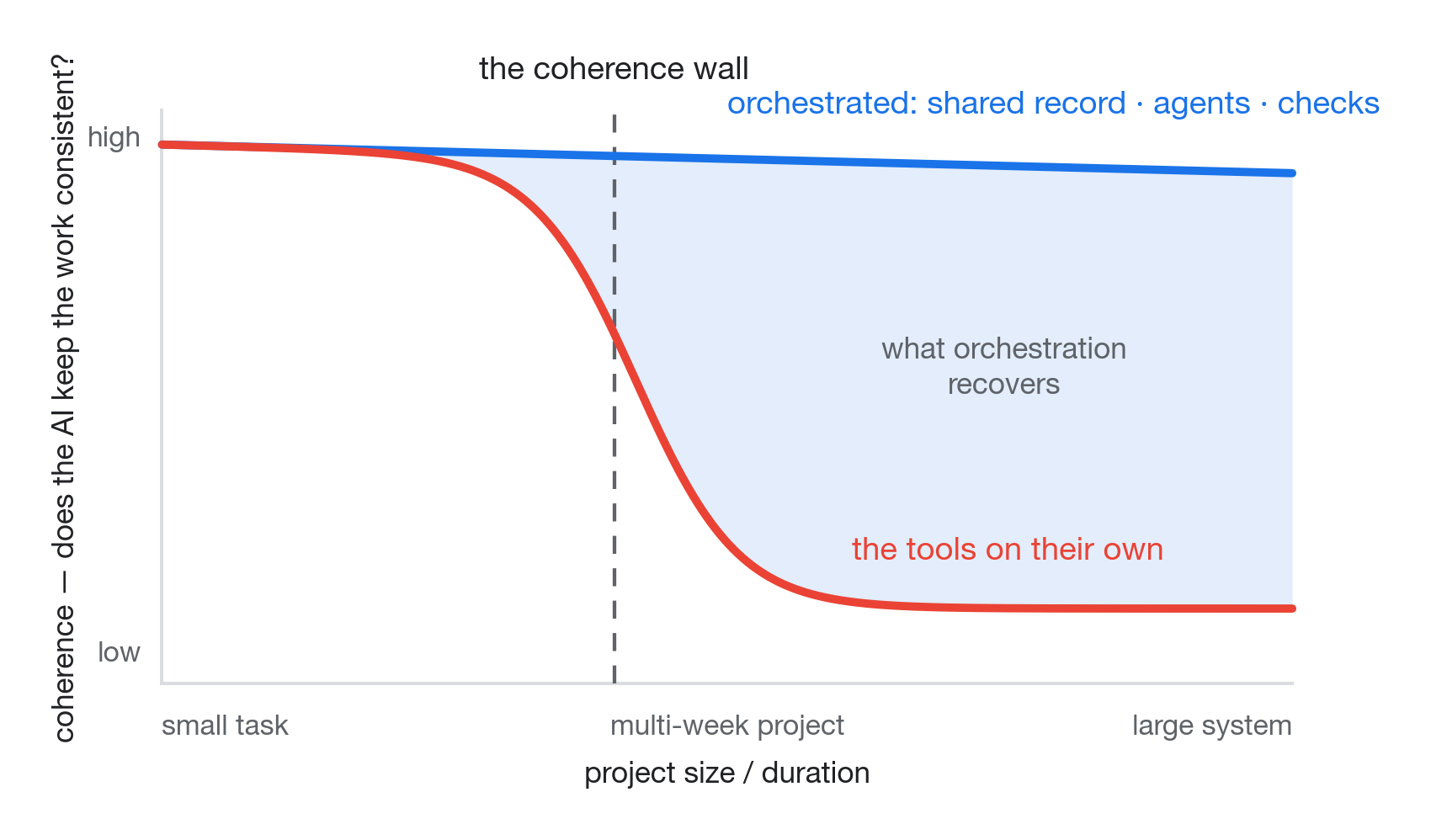
The coherence wall. On their own, the tools hold up on small, well-scoped work, then drift as the project grows; the orchestrated path holds across the range. Closing that gap is what this system is for.
Coordination, not intelligence
What I came to think, building and dogfooding Crucible, is that this is more of a coordination problem than an intelligence problem. The model wasn’t losing track because it wasn’t smart enough. It was losing track because the relational structure of the project lived in my head, not in anything the model could read. The fix that worked for me was to give the AI a shared, structured record of the project to work against — every requirement, design, decision, code file, test, and the typed relationships between them, all queryable. Once that record existed, session drift dropped drastically. Everything else — the multi-agent coordination, the phase gates, the audit-ready paper trail, the learning loop — fell out of that one choice.
One placement note, so the shape is clear from the start: Crucible is not another coding agent, and it doesn’t replace the one you already use. It’s an orchestration layer that runs on top of one — today, Claude Code — coordinating specialized sessions of it against the shared record and governing what each is allowed to do. When the underlying agent gets better, this layer gets better with it.
Here’s the whole system that fell out of that one choice:
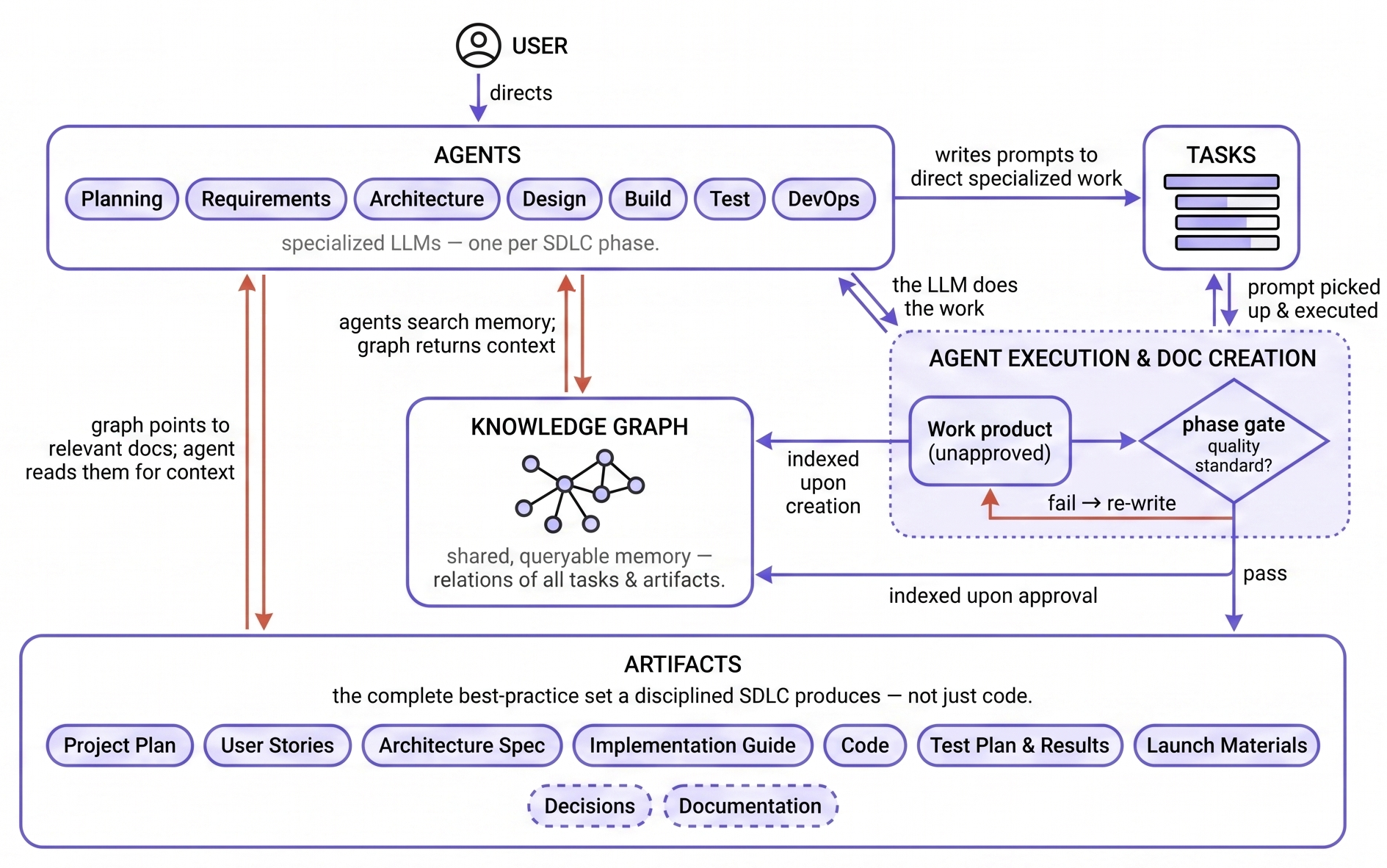
The whole loop at a glance. A user directs specialized agents, one per SDLC phase; the agents write tasks; a task is executed into a work product that must clear a phase gate before it becomes an accepted artifact; everything is indexed into the shared knowledge graph the agents read from.
What I’m claiming — and what I’m not
Before the details, here’s what I’m not claiming, because it’s easy to read more into this than I intend.
It does not design your software. The hard part of a large system was never the volume of code; it’s the abstractions — structures designed to absorb requirements nobody has determined yet. That is anticipatory judgment, and in this design it stays human. Crucible doesn’t make those bets for you. What it does is keep months of execution coherent with the bets you made — and when the undetermined requirement finally arrives, “what does this change touch?” is a graph query, not a memory exercise.
It does not bring its own quality bar; it enforces yours — imperfectly, and at scale. The output quality is a function of the standards the operator encodes. Acceptance criteria are the mechanism: state your bar once and the gates apply it on every relevant task, whether or not you are in the room. That enforcement is not perfect — the actor being governed is a probabilistic model, and some fraction of the work still needs your eye — but applied en masse it covers the vast majority, and what slips through you catch the way you would with a capable new teammate: audit, review, course-correct. The correction load should shrink from both ends over time, as the underlying models improve and as the governance and orchestration tighten around them. A newer builder gets discipline they wouldn’t have known to impose; an experienced engineer gets their own standards enforced at a scale one person can’t police by hand. Either way, the ceiling is the operator plus the model: the system raises how consistently you hit your own bar, not the bar itself.
Where I’d expect it to work first. Everything it’s proven on so far is my own work — and that work is the kind most organizations actually run on: internal tools, business-process systems, a CRM, release tooling — the broad middle of software, where the realistic alternative is a stretched team, a contractor, or nothing. Code that consistently meets an encoded standard, with full traceability, is an improvement on how that software usually gets built. If it transfers anywhere first, it’s there: one capable person covering more scope than they otherwise could, with a record that doesn’t live only in someone’s head. If your problem is inventing novel abstractions, Crucible will keep the work around them coherent; it won’t invent them for you.
One shared record for every agent
Start from the problem: a single model session can hold only so much before it loses the thread. That bound goes up every release, but it never disappears — there’s always a unit of work too big for one session. How do people handle work too big for one person? We break it down: requirements, design, implementation, testing, with handoffs between them. The same move works for AI.
But decomposition alone isn’t enough — the pieces have to stay coherent with each other. That’s the part that breaks when you just open more sessions. So the design choice is: connect semantic reasoning to code through a shared structured record, and let every session read and write that record instead of its own drifting copy.
The reasoning chain from there is short. If you have specialized agents for each phase, they need to assign each other work — so, tasks. If they’re doing real work, they produce real artifacts — requirements, designs, acceptance criteria, code, tests, review notes. Once you have artifacts and a process that links them, you have a graph: typed nodes for the artifacts, typed edges for the relationships — implements, depends on, verifies, supersedes. Wire retrieval over that graph and a session can pull not just text that looks similar, but the structurally relevant piece — the design this code implements, the requirement that design serves, the tests that cover it. Having the process build those links as a side effect of the work makes the record more rigorous than teams usually manage by hand, because it’s enforced rather than remembered.
That shared record is the thing. I’ll call it the knowledge graph (the shared, structured memory all the agents work against). Everything below is a consequence of having it.
An agent does the whole job, not just the code
Picture an implementation task the way a senior engineer actually does it — not “write the code,” but the whole job. You read the requirements, the architecture, the implementation guide. You chase the ambiguities down with research and questions until the spec is clear. You break the work into pieces. You build each piece, test it, check it against its acceptance criteria, and only then move on. You integrate the pieces, test the whole, and sign off. You commit the code and write the as-builts. You log the test plan and the results. You hand the baton to whoever’s next — assign them their tasks — certify that every item is done, and close out. That is the job.
Most AI coding tools help with one line of it: writing the code. I went looking for one that made the model do the rest — the comprehension, the decomposition, the verification against criteria, the documentation, the handoff, the sign-off — and didn’t find it, so I built it. Implementation is just one role: each specialized persona runs its own version of that disciplined workflow, flexible and creative inside each step, gated and governed between them. The rest of this post is the substrate that makes that possible.
Seven movements
We’ve seen the whole loop at the top. Now each part of it in turn — each framed as the question the previous one raises.
1. The record maps everything to everything
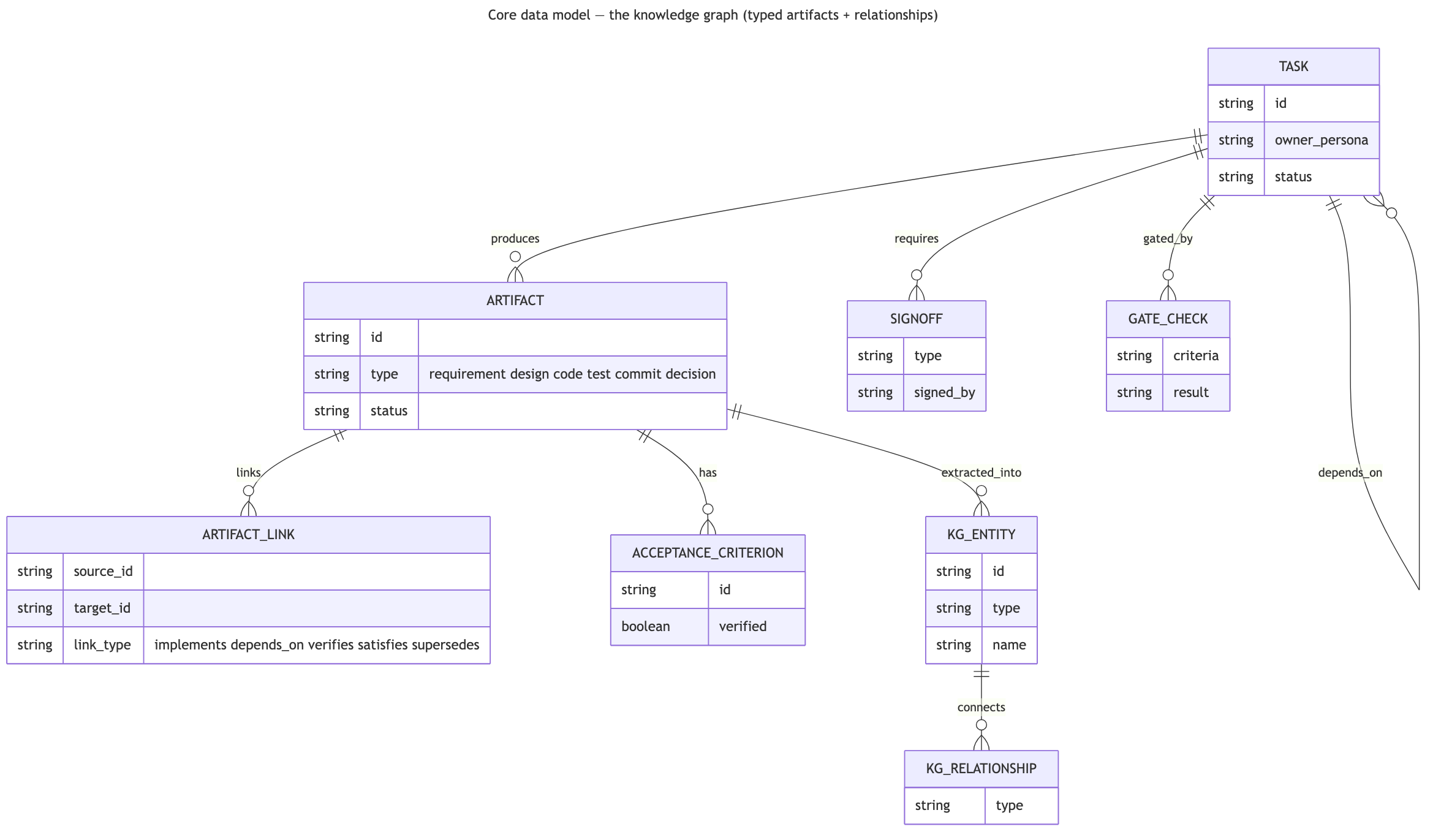
Every artifact across the lifecycle — user stories, designs, acceptance criteria, decisions, code files, tests, tasks, commits — is a typed node in the graph, joined by typed edges. The links are real relationships you can traverse, not free-text tags: a git commit is a first-class node carrying an edge to the acceptance-criterion node it satisfies, which carries an edge to the design that called for it, which edges back to the requirement that drove the design. So when you find a bug, tracing it to the code, to the design behind that behavior, to the requirement that drove it is a graph query, not a memory exercise — and the reverse query is just as cheap: what other code implements this same requirement, what other tests cover this acceptance criterion. The fix stops being a patch and becomes complete, because the graph shows everywhere the same root cause reaches.

Every link is a typed edge you can traverse in either direction. Start from a bug and walk backward to the requirement that explains why the code exists; or walk forward from a changed requirement to every design, test, and file it touches. Both are graph queries, not memory.
The reverse direction matters as much. Change a requirement after testing has started, and the system surfaces every design, file, test, and open task affected — ranked by how structurally close each is. You know what to update, and in what order. And the links are built as you work — write the requirement, the link is made; commit the code, the link is made. The record isn’t a documentation chore; it’s a side effect of the workflow.
→ Traceability across thousands of artifacts is useless if every query is slow. How does it stay fast and cheap?
2. Retrieval runs local and frugal
The retrieval layer runs on your own machine — the work of finding the relevant context is local, and the graph itself lives in a local database. The only thing that goes anywhere external is the reasoning call to the model, and even there the system is careful: instead of dumping everything related into the prompt, it sends the structurally relevant slice — the closest candidates plus the few critical neighbors and prerequisites the graph says matter. The token budget gets spent on signal, not noise. A useful side effect: your project’s structure and history stay on your machine; the model call is the only thing that leaves.
→ Fine for one developer. What about a team of agents working at once?
3. Agents share the record, not messages
A team of specialized agents — requirements, architecture, implementation, testing, and supporting roles — work at the same time on different parts of the same project. They don’t share a chat thread and they don’t pass everything they know to each other in handoffs. They share the record. Requirements writes a story; the link to its epic is automatic. Architecture reads the story, writes a spec; the link is automatic. Implementation reads the spec, writes code, links the file. By the time testing runs, every prior agent’s work is already in the record — testing isn’t asking implementation what it did, it’s reading the result.
This is the load-bearing distinction. Message-passing is fragile — every handoff is a chance to lose context. A shared record is durable — the next agent reads everything that came before. That was the first thing I made structural when I started building Crucible properly.
→ If they’re all working at once, how do they not collide — and how does the system know what should run next?
4. The graph knows what depends on what
Because the record holds dependencies as first-class relationships, the structure of the work is queryable, not just the artifacts. Ask which piece is blocking the most downstream work and you get the critical path; ask how far a requirement change will ripple and the system traces it forward across the affected designs, files, and tests. You direct the sequencing, and the graph keeps you honest about what actually depends on what.
This reduces the most expensive class of mistake. In ordinary development, agents (or people) start work that depends on something not yet finished, build on assumptions, and redo it when the dependency lands differently. With the dependency structure explicit, you stop building on ground that hasn’t settled. In the alpha the structure is captured and queryable, and you drive the sequencing.
Driving that sequencing automatically is part of the Pro direction, and it is worth seeing why it belongs there rather than in the alpha. Because Pro puts the orchestration first, it can afford much richer data structures behind the record — and richer structures are what make robust graph algorithms possible: dependency mapping, graph traversal, graph-informed retrieval. With those in place the system can order the work itself, taking the independent (MECE) items first and resolving dependencies in sequence so the whole flow carries less friction. That is a capability the orchestration-first architecture earns; it exists in Pro, and I am integrating and testing it now.
→ That orders the work. What keeps the work itself honest — what stops an agent skipping a step?
5. Deterministic gates keep a mercurial model honest
The model is mercurial by nature, and no orchestration layer changes that — it will sometimes skip a step, lose the thread, or claim something is done when it isn’t. The design response is a deterministic boundary around that probabilistic actor: state machines and gates that read the shared record and decide what is allowed to happen next.
Behind that boundary is a real architectural choice — who orchestrates? — and there are two answers, each with trade-offs:
- Model-as-orchestrator. The model is in the driver’s seat: it decides what happens next, and the surrounding code is its tools. This is much easier to build and works well a great deal of the time — which is exactly why Crucible’s alpha starts here, with the deterministic gates acting as guardrails that catch the model when it strays.
- Orchestrator-calls-the-model. The deterministic layer holds the seat, and the model is a step it calls to advance the work within a structure it doesn’t control. This is considerably harder to build; what it buys is determinism — much tighter control over what the system does, and in what order. That’s the direction Crucible Pro is built toward.
These aren’t rival camps so much as a path. The structure you work out to make the first version solid — the typed record, the artifacts, the gates, the acceptance criteria — is exactly what the second one needs to get right. Alpha earns that structure; Pro puts it in charge.

Two ways to wire the same parts. Model-centered keeps the model in the driver’s seat — much easier to build and good much of the time, which is where the alpha lives. Record-centered makes the model a step the structure calls — harder to build, but tighter and more deterministic, which is where Pro is headed. The same record and gates sit underneath both.
Either way, the gate’s decision is a matter of physics rather than persuasion. A check either passes or it does not — it is not a judgment call the model can argue with. So when an implementation agent tries to claim a task before the requirements and design are signed off, the claim is refused outright, and the error tells the agent exactly what is missing. The same gate stays smart about evidence, because rigidity without judgment would be its own failure: if the formal design signoff is absent but every acceptance criterion has been independently verified, the gate allows the claim and logs the exception to the audit trail.
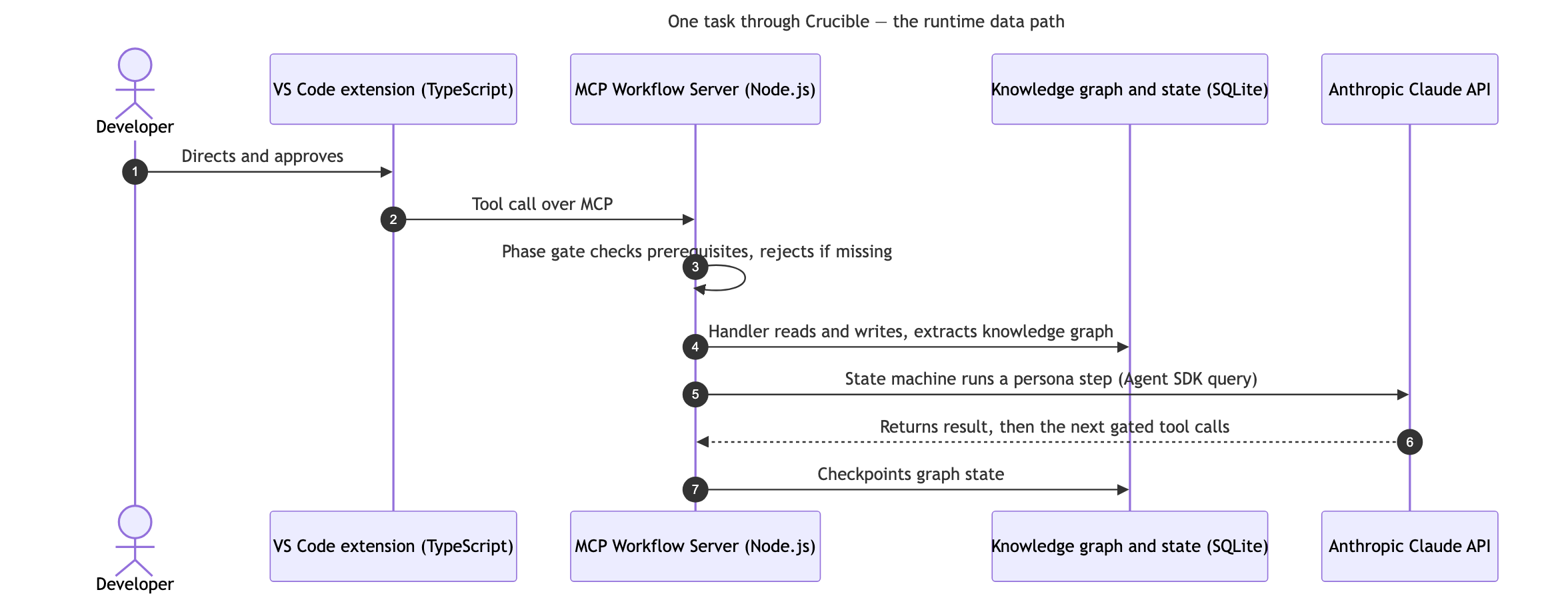
The checks run at the call layer. Before a tool call leaves an agent, the system asks whether there is evidence the tests actually ran before this “complete” call, and whether a handoff to the next phase exists before this one closes. If the answer is no, the call is blocked before it executes, and the agent is told precisely what to correct. In strict mode the agent then retries — it reads what the gate rejected, fixes the gap, and submits again, iterating until the work satisfies the check. That loop is not the most efficient path, but iterating toward a correct result is a great deal better than shipping a mistake. The honest way to describe what this buys you is not prevention but a far higher catch rate: the system catches more errors, earlier, through structure rather than through you happening to notice. Quality is enforced by the system’s structure rather than by hoping the model remembers, and that is the difference between a process that is advisory and one that is architectural.

The rejection is programmatic, not conversational. The gate returns a machine-readable reason and the exact correction, and the session iterates against it until the work passes — the system behaving like a compiler for the development process, not a reviewer leaving comments.
→ Rules handle the predictable cases. What about genuine judgment calls?
6. Judgment routes to a human
Some decisions have no rule — two valid designs, both in scope, a real trade-off. Instead of guessing or burying a vague question in chat, the agent opens a structured decision: the options side by side, the trade-offs, the relevant prior decisions pulled from the record. The human decides, and the answer becomes a first-class part of the record — so six months later “why did we go this way?” is a query, not a memory test. When a call is contested, the protocol escalates in graduated steps rather than forcing a yes/no. The system’s job is to know when to ask and to make the question cheap to answer well.
→ That handles a decision once it arises. How does the system get sharper over time?
7. The record learns the team
Every interaction feeds the record. Useful answers reinforce the patterns behind them, links that people accept become positive examples, and links that people reject are remembered so the system stops suggesting them. None of this is model retraining; it is structure accumulating about how this team actually works and what is genuinely coupled.
There is a sharper version of this worth naming, because it answers a real frustration with using an AI coding tool on its own. When you correct a model in a chat session, the correction evaporates when the session ends, and you teach the same lesson again tomorrow — your effort never accretes the way it does with a person who internalizes it. Crucible’s answer is to move the lesson off the model, where it cannot stick, and into the acceptance criteria, where it can. A hard-won standard — migrations require a rollback plan, no endpoint ships without an auth check, every public function carries a test — can be encoded once as an acceptance criterion, and from then on the gate applies it on every relevant task without your restating it. The teaching becomes encoding, the recurring cost of re-explaining becomes a one-time investment, and the standard is enforced whether or not you are in the room. Getting those criteria precise is real work, and it is the part that takes care, but it is the mechanism that makes a lesson stick rather than evaporate.

The same correction on two tracks. LLM alone, the lesson evaporates with the session and you re-teach it forever. With Crucible, you encode it once as an acceptance criterion and the gate enforces it from then on — the lesson moves off the model, where it can’t stick, into the record, where it can.
A new engineer ramps by querying the record the way they would query a codebase: what is here, what was touched recently, and what decisions were made and why. The codebase stops being just artifacts and becomes a navigable history.
A system, not a toolkit
The seven movements read like a line because that’s how you walk them. But the architecture isn’t a line — it’s a network, and the single fact that makes it one is this: every part reads from and writes to the same record. Mapping reads it. Retrieval pulls from it. Parallel agents coordinate through it. The gates check it for evidence. The decision protocol composes its questions from it. The learning loop writes patterns back into it.
That’s the difference between a system and a toolkit. The pieces don’t just coexist next to each other — they reinforce each other, because they share one source of truth. Adding another agent shouldn’t degrade quality the way it does in message-coordinated systems, because the marginal cost is small when the record is shared. The gates aren’t brittle, because they read evidence from the same place the work is recorded. The system can get sharper with use, because the learning has somewhere to accumulate. None of that is possible without the one design choice; all of it falls out once you make it.
Orchestration compounds as models improve
Three things make me think this is the right layer to build on, and that it gets stronger over time, not weaker. Underneath all three is one idea: a problem bigger than your best engineer isn’t solved by engineering a smarter human, or by just adding more humans — it’s solved by an organization, with decomposition, process, specialized roles, and a shared record. Crucible is that, for AI agents. A better model is a more capable individual; the organization is what turns capable individuals into more than the sum of their work — and it matters more as they improve, not less.
It coordinates the model; it doesn’t try to be the model. The foundation labs have orders of magnitude more capital, talent, and compute than any individual or small team, and from what I’ve seen, anything built to out-model them has a shelf life of about one release cycle. The coordination layer — the record, the gates, the learning, the audit trail — sits in territory they don’t seem to be in the business of occupying. So I built there.
It compounds as the models improve. A single model call today handles roughly a well-scoped task a junior engineer could do, or a section of a design doc. That bound keeps rising. As it rises, the orchestrated work-scope rises with it in absolute terms — if one call handles a task and the orchestrated system handles a small-team-week today, then when the model doubles in capability the orchestrated system should handle a small-team-month. The gap between one-call work and orchestrated work widens as models get better; it doesn’t close.
It’s agnostic to whatever ships next. The record, the gates, the coordination, the learning loop don’t depend on what the model is internally. When a successor to today’s architectures arrives, the plan is: plug it in, keep coordinating. The model is whoever’s doing the reasoning today; the structure is the part that makes the work hold together.
Everything on your machine
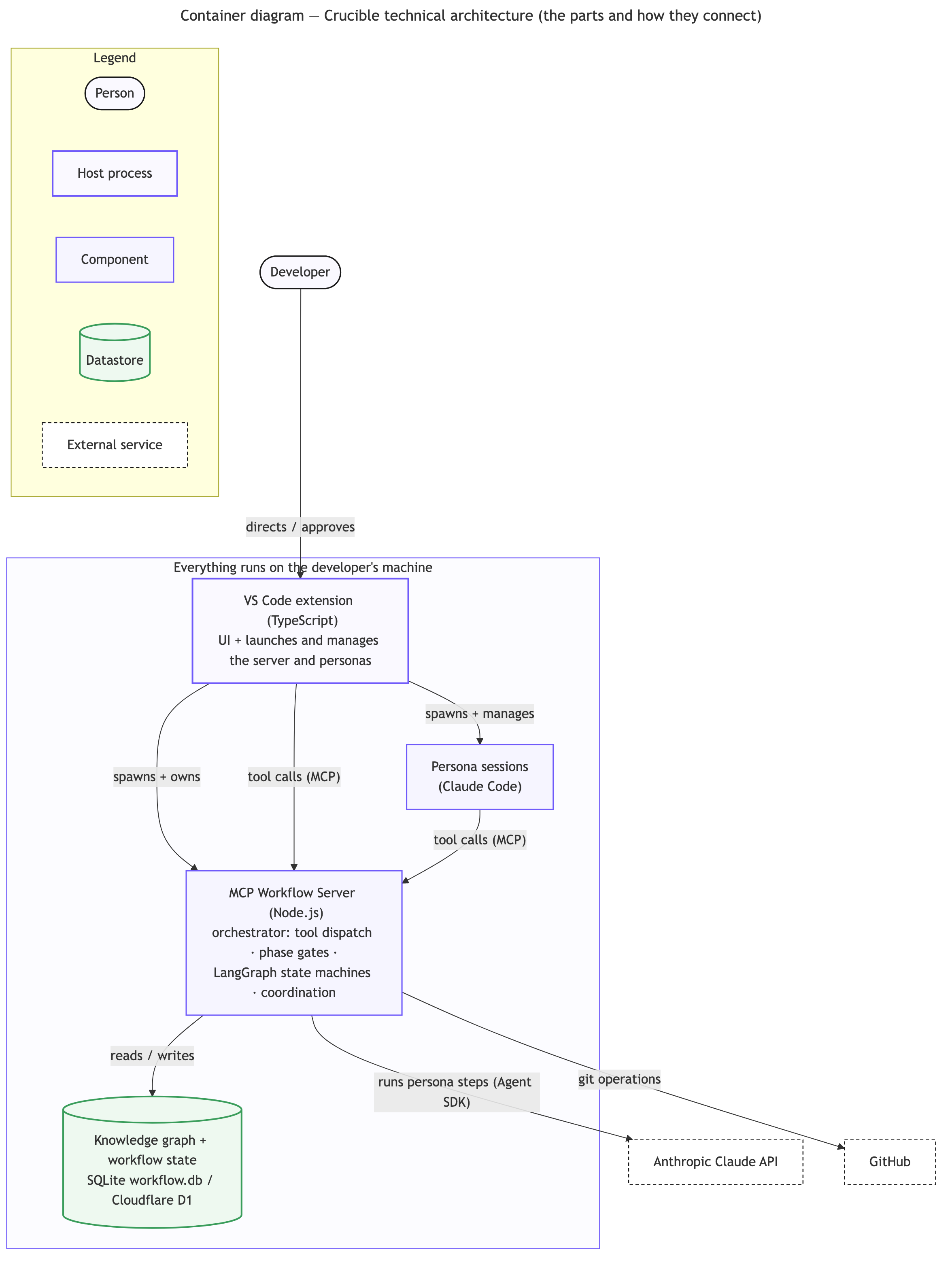
Everything above is the shape and the reasoning. For the reader who wants to confirm it’s real, here is the machinery — drawn from the actual codebase, naming the real stack. (The one thing kept deliberately categorical is the retrieval/ranking internals; everything else is named.)
The parts, and where they run. Crucible runs entirely on your machine: a VS Code extension, the persona Claude Code sessions, the MCP Workflow Server that orchestrates them, and one local SQLite database that holds the knowledge graph and all workflow state. The only outbound calls are to the model API and GitHub.
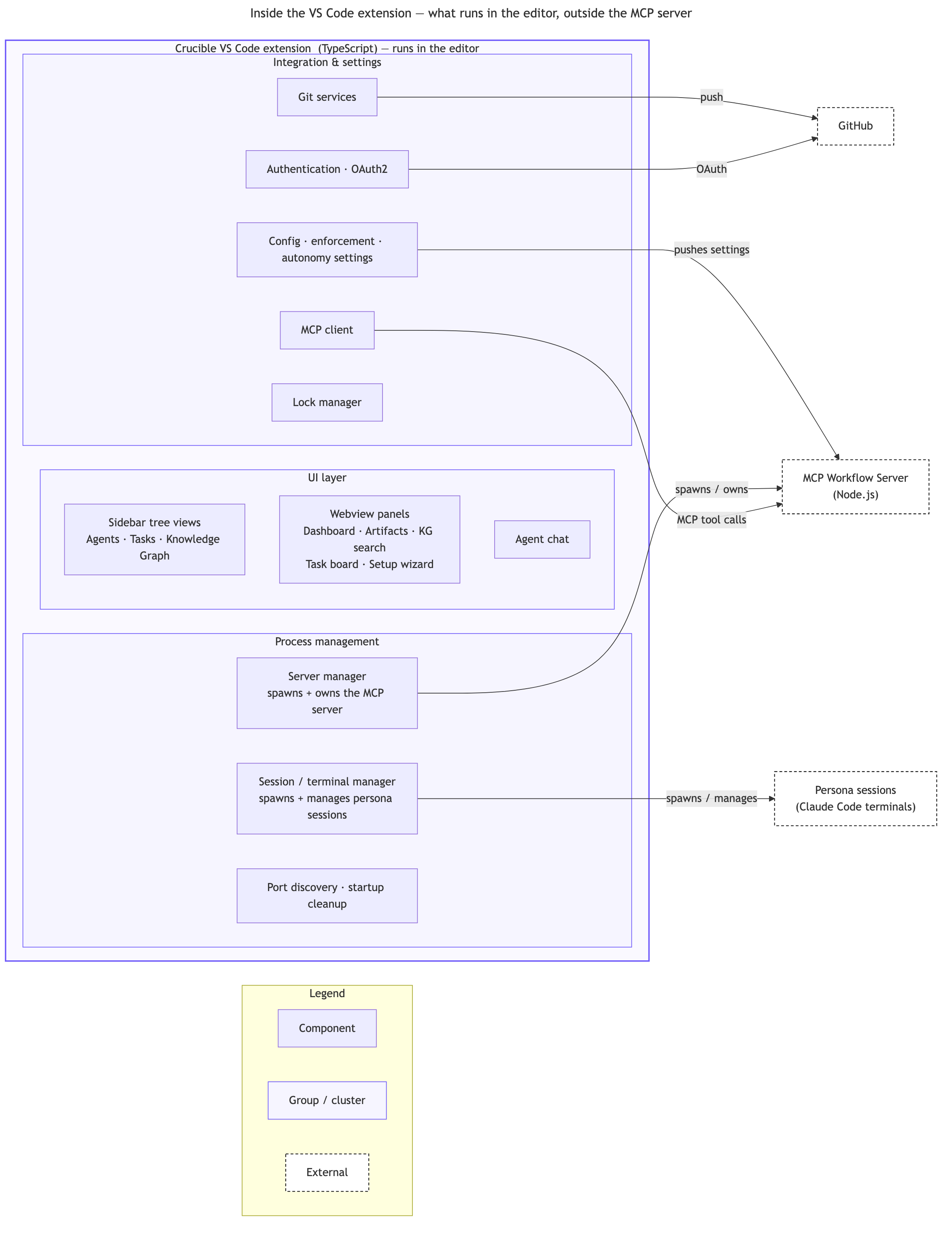
What lives in the editor. The extension is more than UI. It is the host that launches and governs everything: it spawns the MCP server, spawns and manages the persona sessions, and carries the integration and settings logic.
Inside the orchestrator. The MCP Workflow Server routes every tool call through a phase gate before a handler can touch the record; a separate orchestration layer (LangGraph state machines) runs persona steps through the model adapter and checkpoints its own state back into the database.
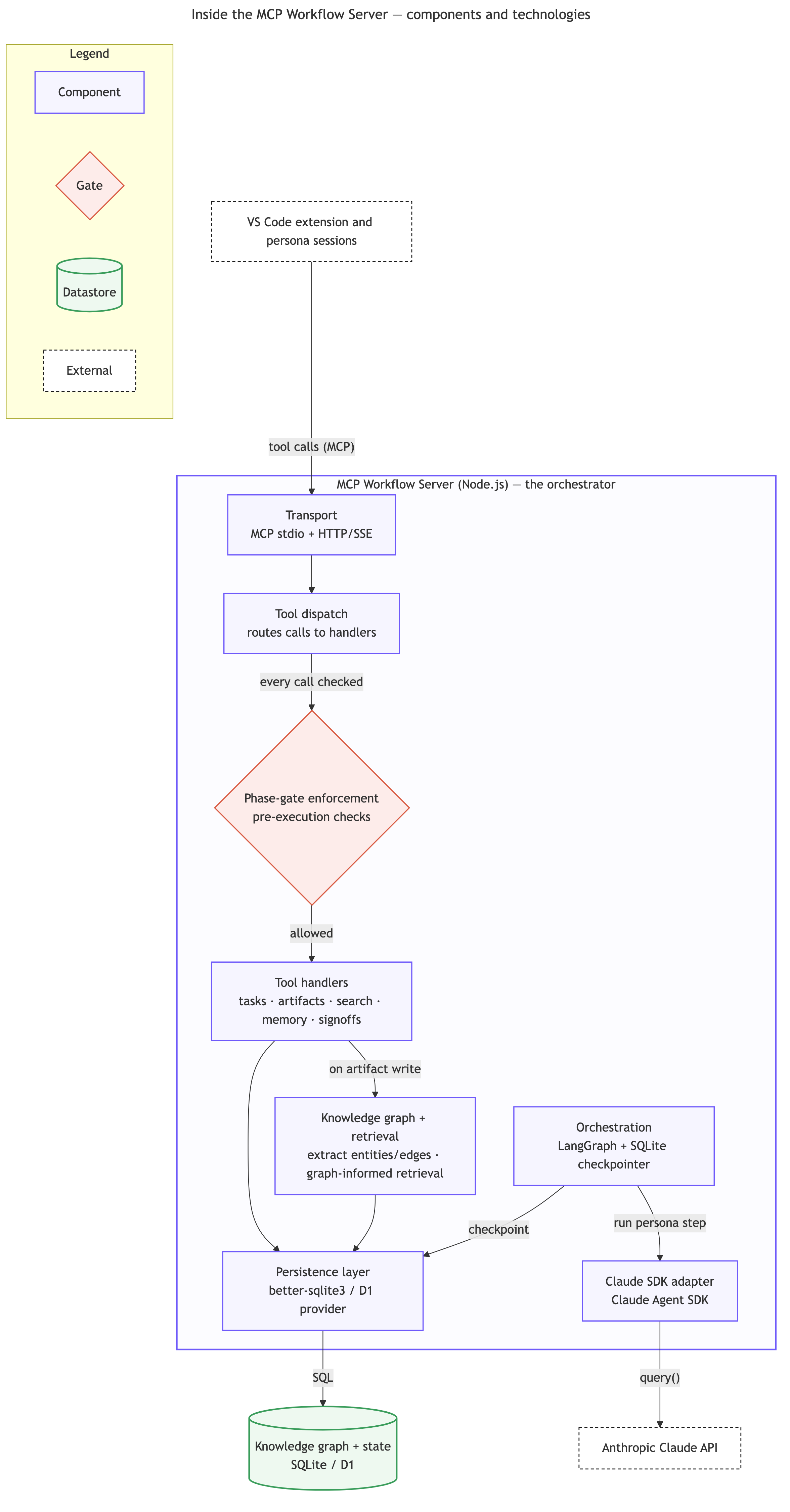
The record itself. Everything is a typed node joined by typed edges — the knowledge graph that makes traceability a query rather than a memory exercise.
One task, end to end. What actually happens at runtime as a unit of work moves through the system.
How it ships. There is no server to trust: a CI pipeline builds and signs per-platform installers, and the product runs locally after install.
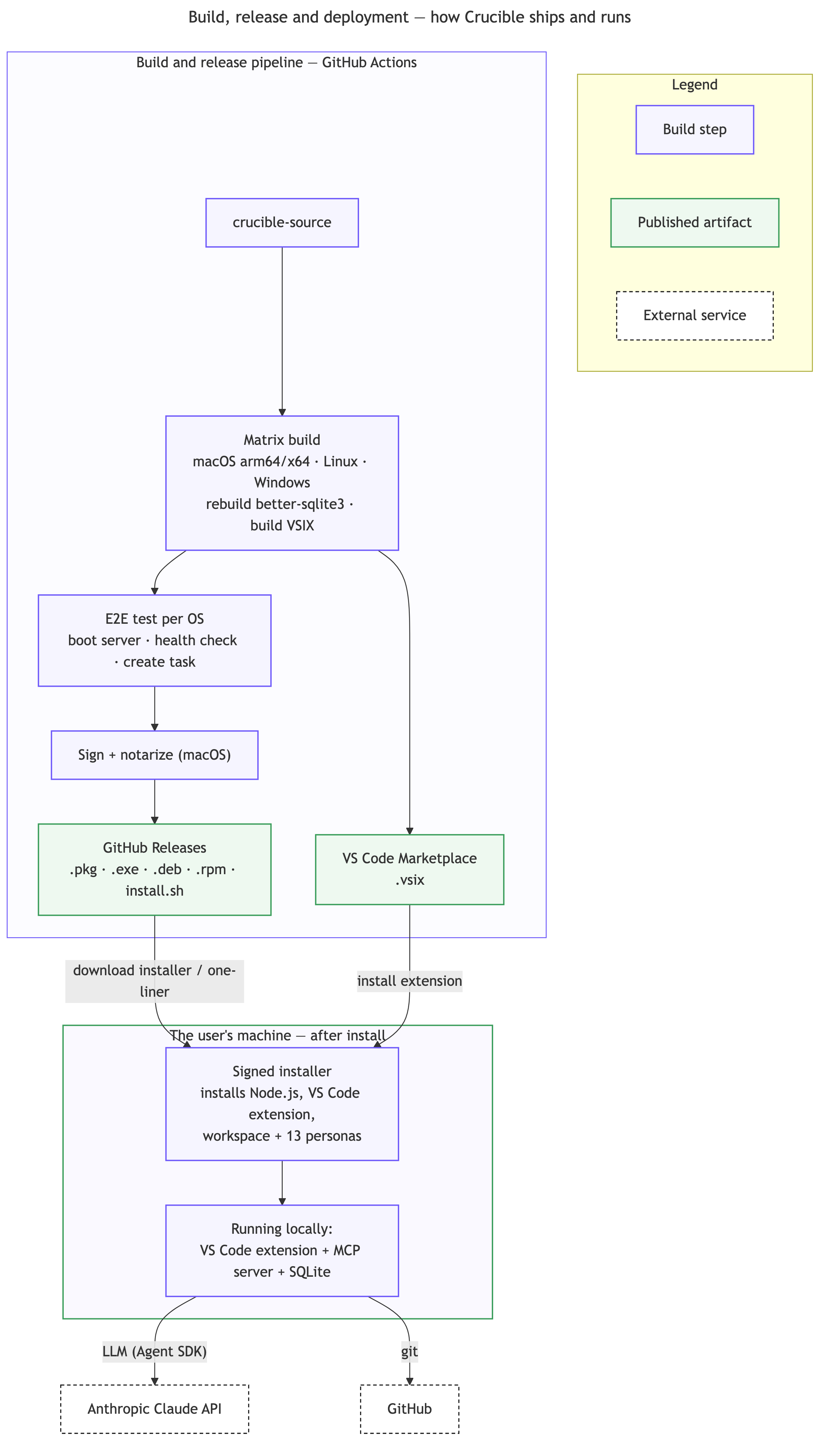
The common thread across all six: there is no hosted backend and nowhere your code or the project record is sent. The orchestration, the knowledge graph, and the model calls all run on your own machine — which is also why it is free to install and why your work never leaves it.
Crucible built Crucible
The strongest evidence I have that this works is that Crucible was built using Crucible. The first usable version coordinated the work that produced the next. The phase gates blocked my own implementation tasks. The decision protocol resolved my own ambiguities. The learning loop clustered my own recurring problems. The system that built the architecture is the architecture.
That’s an existence proof, nothing more: one operator, about three months, on a regular Claude subscription, with the system coordinating its own construction. The released platform is comparable in size to the codebase of a mature open-source project like Redis, and the same window also produced a visual-asset builder, a CRM in operational use, several websites, a small game, and the cross-platform release tooling. The record that coordinated all of it holds 12,365 linked entities and 27,754 relationships in the main workspace — not a demo, the actual development history. (The size and cost estimates, and why I discount them hard, are in the launch essay.)
What it doesn’t tell you is whether the code is any good. I can’t show defect rates or maintenance costs over time from the build itself: the instrument was changing underneath the measurements — Crucible was rebuilt continuously by successive versions of itself, so a defect rate from early in the build correlates to a tool that no longer exists. That data has to come from a fixed version, applied to projects it didn’t build, and that’s part of why the alpha is out now. The numbers above are evidence the approach holds together at scale; they’re not a quality verdict.
Why alpha, and why it’s free
Alpha exists now for a simple reason: the system is already powerful on its own. I’d been using Claude Code for everything — genuinely capable, but I kept hitting the same wall as projects grew. With the structure around it, the wall went away: today the alpha makes me multiples more productive and has built working codebases well past the scale where the tools on their own fall apart. Pro takes that further, but the alpha isn’t a trailer for it — it’s a real tool delivering leverage now. And because the value lives in the workspace rather than any one session, Pro is meant to build on the workspaces you’ve already created — a plug-in step, not a migration, so the work you put in carries forward. Starting now should cost you nothing later.
Releasing it now also serves a second purpose I care about: getting it into the hands of people building real software surfaces inputs I cannot generate alone. Real usage shows me where the governance needs hardening first, which parts of Pro matter most, and how the architecture holds up against problems I have not personally hit. Engaged early users have a genuine hand in what this becomes, and that exchange is part of why the alpha is out in the world rather than held back until everything is polished.
And it is free for a reason that comes down to conviction rather than tactics: I do not think the orchestration layer should be the thing you pay for. You are already paying your model provider, and for the kind of work where I kept hitting that wall, I think you are better off building with this structure around the model than without it. Offering it free is the most direct way I can act on that belief.
Alpha referees, Pro drives
Two lines run through what comes next, worth naming first. Alpha is out now, and beta is hardening its enforcement — together they’re the reactive foundation: the model orchestrates the work, and the gates catch it when it strays. Crucible Pro, in active development, is the proactive direction — the orchestrator drives the model rather than refereeing it, on richer data structures and graph algorithms.
This is alpha, aimed at individual engineers and small teams, and I would rather you hear the limits from me. Because the model is mercurial, the agents do genuinely good work but still need active guidance, and the right mental model is a capable new teammate who needs direction rather than a hands-off autopilot. Two more limits. Every number in this piece is single-operator evidence — I built it, I ran it, I judged it — and nobody should mistake that for an audited benchmark. And the requirement layer has only ever had one voice in it: mine. The structure is designed for more — decisions are owned artifacts, contested calls escalate through a graduated protocol rather than a yes/no — but how it holds when several people with different instincts write requirements and acceptance criteria into the same record is untested, and I won’t claim it survives that contact until it has. Governance hardening is in progress as I write this — current alpha is a little soft on enforcement, and the stricter behavior is landing over the next few days. One piece of the learning loop, the unified cycle gate that records every deviation, is fully coded but not yet wired into the active runtime, so it is not firing on every checkpoint today; the pattern is real in the code, and the final activation is on the list. Crucible also skips the heavy external-launch work — accessibility, internationalization, failover, and formal security and legal review — that a public consumer product carries. What it has instead is an unusually complete paper trail and more thorough testing than most internal projects bother with.
The clearest way to understand where this is going is the way the orchestrator relates to the model. In alpha, the orchestrator is reactive: the model acts, and the system monitors, catches, and course-corrects it — refereeing a mercurial actor and, in strict mode, making it iterate until it passes the gates. Crucible Pro, which is in active development, takes this in two directions. The first is depth in the data structures behind the artifacts — richer capture, indexing, and search, so the system gets far more out of the record it maintains. The second, and the real differentiator, is a shift in posture: Pro moves the orchestrator from monitoring the model to driving it — from catching a wandering actor after the fact to constraining its path before it wanders, so there is less to catch. Alpha gives you the structure and the catch points while you, the engaged operator, close part of the loop; Pro is about the system holding more of that loop itself. There is a useful way to feel the difference: alpha instills the rigor — the gates will not let sloppy or out-of-order artifacts through, so working in it pulls the work into real SDLC discipline whether or not you arrived with it — and Pro automates that rigor into velocity once the discipline is in place, driving the model through the process the team has already internalized. The honest line is that alpha is the foundation, and the proactivity is the direction.

Same substrate, different posture. On the left, alpha today: a single agent per phase, the orchestrator refereeing — it monitors, the gate catches, the operator helps close the loop. On the right, the Pro direction (in development): the orchestrator holds the seat and drives, dispatching parameterized work to parallel sessions and committing only what clears the hardened gates. The knowledge graph underneath is the same; what changes is who is driving.
It works for me, and it compounds
One move carries the whole design: put a shared, structured record at the center and have every agent work from it. Coordination, the quality gates, the audit trail, and the learning loop all follow from that — the model does the reasoning inside the structure, and the structure keeps the work coherent as it grows.
And within that boundary — you supply the judgment and the standards; the system holds the work coherent with them — it already works for me. The released platform was built in about three months by one operator directing these agents — Crucible built using Crucible — and the alpha makes me multiples more productive today, at a scale the tools on their own could not hold. What I’m most excited about is the direction it sets up: because it coordinates the model rather than trying to be the model, it should only get stronger as models improve, not obsolete. Crucible Pro is the next step on the same structure — the orchestrator moving from catching a wandering model after the fact to driving it before it wanders. Alpha is the foundation; that’s where it’s headed.
Crucible is free and open to install. You bring your own model access and pay your provider directly — no markup, and no lock-in on which model you use. The orchestration layer should not be the expensive line item; your model usage is the real cost, and you should own that relationship.
If you want to see it work, install it and point it at something real — the getting-started guide is the on-ramp. When something breaks or surprises you, tell me: alpha feedback decides what gets hardened first. If you run it with more than one voice setting requirements, I especially want to hear what breaks — that is the next claim in line to be proven. And if you’re working on similar problems, I’d be glad to compare notes — the architecture is open in both directions, and the interesting part is how it composes with everything else.
It changed how I build. Whether it changes how you build is what I’m trying to find out.
The story behind the build — and the math on what three months of it produced — is in the launch essay.
Crucible is a free AI software-development platform from Ember Agentic Labs that builds working, tested software by directing specialized AI agents — crucible.emberagenticlabs.com. Built by Tony Gibbons.